
前回に続いて、データセットに含まれるテキストの中身の理解を深めます。
そのために、トピックモデルのひとつである「潜在的ディリクレ配分法(LDA)」を使用して、テキストの内容を分類して、データセットにどのような文章が含まれているかを確認してみます。
さらにその結果を、pyLDAvisを使って可視化します。
目次
- はじめに
- トピックモデルとは
- 潜在的ディリクレ配分法とは
- pyLDAvisとは
- 環境
- 前処理
- データの読み込み
- テキストデータの前処理
- テキストデータをBag of Words(BoW)形式に変換する
- LDAを実装する
- ワードクラウドで可視化する
- 補足: Perprexityを使って、トピック数を考察する
- まとめ
はじめに
トピックモデルとは
トピックモデルとは、自然言語処理において、大量のテキストデータから「トピック」と呼ばれるテーマや主題を、自動的に抽出するための統計的手法です。
潜在的ディリクレ配分法とは
潜在的ディリクレ配分法(LDA)とは、文書の集合から、その文書に潜在的に存在するトピックを識別するための確率的な手法です。最も広く使用されるトピックモデルの一つです。
pyLDAvisとは
pyLDAvisは、Pythonのライブラリで、トピックモデルの結果を視覚的に探索・解釈するためのツールです。特に、潜在的ディリクレ配分法(LDA)の結果を視覚化するのに適しています。
環境
以下の環境で実行します。
- OS: macOS Ventura 13.5.2
- Python: 3.10.6
- ライブラリ:
- pandas==2.1.0
- matplotlib==3.7.2
- spacy==3.6.1
- pyLDAvis==3.4.1
- wordcloud==1.9.2
- neologdn==0.5.2
前処理
データの読み込み
準備編:chABSAデータセットを感情分析のために整形するで作成したデータを使用します。事前準備として、データを読み込みます。
■python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# データの読み込み
df = pd.read_csv('../data/interim/chabsa-sentiment-analysis.csv')
df.head()

テキストデータの前処理
潜在的ディリクレ配分法(LDA)に入力するデータを作成するため、テキストデータを整形していきます。
全角・半角を統一する
全角・半角の統一には、neologdnライブラリを使用します。
■python
# 全角・半角文字を統一する
import neologdn
def apply_neologdn(text):
return neologdn.normalize(text)
# 全角・半角文字を統一する
df_lda['sentence'] = df_lda['sentence'].apply(apply_neologdn)
df_lda.head()

桁区切りの数字を削除する
桁区切りの数字を、
- 「1,000 → 1000」のように桁区切り文字を削除した上で、
- すべての数字を「0」に置き換えます。
データを文字列として扱う場合には、そこに書かれている数字自体の情報は、あまり意味を成さないため、置き換えてしまいます。
■python
# 桁区切りの数字を削除する
import re
def apply_remove_comma(text):
"""文字列中の数値を0に置き換える"""
text_removed_comma = re.sub(r'(\d+)[,.](\d+)', r'\1\2', text)
text_replaced_number = re.sub(r'\d+', '0', text_removed_comma)
return text_replaced_number
# 数字を削除する
df_lda['sentence'] = df_lda['sentence'].apply(apply_remove_comma)
df_lda.head()

大文字・小文字を統一する
文章中に現れる英単語について、大文字・小文字を統一します。ここでは小文字に統一しています。
■python
# テキストを小文字に寄せる
def apply_lower(text):
return text.lower()
# テキスト中の英単語を小文字に寄せる
df_lda['sentence'] = df_lda['sentence'].apply(apply_lower)
df_lda.head()

記号をスペースに変更する
文章中で使用されている記号をスペースに置き換えます。
■python
# 記号をスペースに変換する
def apply_replace_symbol(text):
"""記号をスペースに置き換える"""
replaced_text = re.sub(r'[!-/:-@[-`{-~]', ' ', text)
return replaced_text
# 記号をスペースに変換する
df_lda['sentence'] = df_lda['sentence'].apply(apply_replace_symbol)
df_lda.head()

ストップワードを削除する
ストップワードを削除します。ストップワードとは、テキスト内で頻繁に登場するが、特定の分析やタスクの文脈での情報提供能力が低い単語のことを指します。
ここでは品詞によるフィルタリングを行います。具体的には、名詞、動詞、形容詞、副詞のみを抽出します。
■python
# ストップワードを削除する
# ここでは、品詞によるフィルタリングを行う
# 名詞、動詞、形容詞、副詞のみを抽出する
import spacy
nlp = spacy.load('ja_core_news_md')
def apply_nlp_and_remove_stopwords(text):
"""品詞によるフィルタリングを行う"""
doc = nlp(text)
# return [token.text for token in doc if token.pos_ not in ['ADP', 'AUX', 'PUNCT']]
return [token.text for token in doc if token.pos_ in ['NOUN', 'VERB', 'ADJ', 'ADV']] # 名詞、動詞、形容詞、副詞のみを抽出する
# tokensに分かち書きされた単語が入る
df_lda['tokens'] = df_lda['sentence'].apply(apply_nlp_and_remove_stopwords)
df_lda.head()
テキストデータをBag of Words(BoW)形式に変換する
テキストデータをBag of Words(BoW)形式に変更します。Bag of Words(BoW)はテキストを数値的なデータで表現するための手法のひとつです。カラムに各単語、値には、文章中における、その単語の出現回数が格納されるように変換します。
ここでは、scikit-learnのCountVectorizerを使用して変換します。
■python
# テキストデータをBoW形式に変換する from sklearn.feature_extraction.text import CountVectorizer bow_vectorizer = CountVectorizer(analyzer=lambda x: x) vec = bow_vectorizer.fit_transform(df_lda['tokens']) feature_names = bow_vectorizer.get_feature_names_out() # BoW形式のデータをデータフレームに変換する df_bow = pd.DataFrame(vec.toarray(), columns=feature_names) df.head()

LDAを実装する
scikit-learnのLatentDirichletAllocationを使用して、LDAをデータセットに適用します。ここでは、トピック数を4として分析を実行してみます。
■python
# LDAModelを用いてトピックモデルを構築する(Bag of Words) from sklearn.decomposition import LatentDirichletAllocation lda = LatentDirichletAllocation(n_components=4, random_state=42) lda.fit(vec)
その後、pyLDAvisを使って可視化します。
■python
# トピックモデルの可視化
import pyLDAvis
import pyLDAvis.lda_model
pyLDAvis.enable_notebook()
pyLDAvis.lda_model.prepare(
lda, # 学習済みのモデルを指定する
vec, # BoW形式のデータを指定する
bow_vectorizer, # CountVectorizerのインスタンスを指定する
mds = 'mmds',
sort_topics=False # トピック番号をソートしない
)
pyLDAvis.lda_model.prepareを実行すると、以下のような画面が表示されます。左側には、各クラスタを二次元にマップしたときの位置関係が表示されます。右側には、選択したクラスタで頻出する単語の上位を確認することができます。
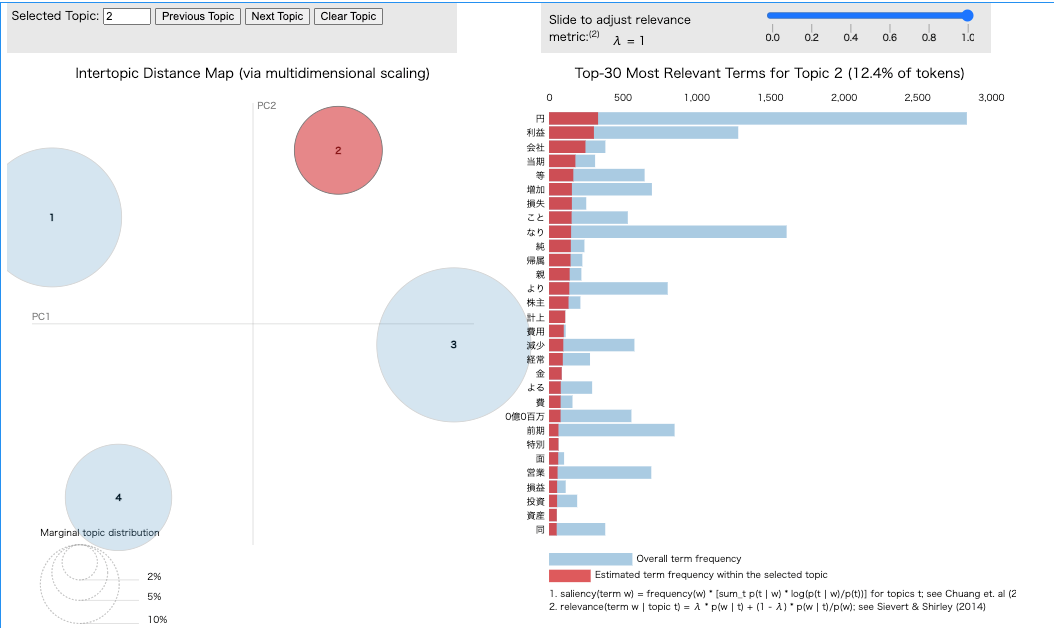
ワードクラウドで可視化する
潜在的ディリクレ配分法(LDA)でグループ分けした各トピックを解釈するために、各トピックに含まれる文字をワードクラウドで表示してみます。ワードクラウドの表示には、wordcloudライブラリを使用します。
■python
# ワードクラウドを作成する
from wordcloud import WordCloud
from PIL import Image
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=(10, 10))
axes = axes.flatten()
for i, topic in enumerate(lda.components_):
wordcloud = WordCloud(
background_color='white',
font_path='/Library/Fonts/SourceHanCodeJP-Bold.otf' # 日本語の場合はフォントを指定する必要がある
).generate_from_frequencies(dict(zip(feature_names, topic)))
axes[i].imshow(wordcloud)
axes[i].axis('off')
axes[i].set_title(f'Topic {i+1}')
この結果を確認すると、以下のようにトピックを解釈することができます。
- Topic1 → 業界や市場などの外部要因についての文章
- Topic4 → これも外部要因についてだが、景気や政策など、よりマクロ寄りの文章
- Topic2 → 自社の業績に言及する文章
- Topic3 → 自社の業績に言及しているが、前期比等で比較している文章

補足: Perprexityを使って、トピック数を考察する
PerplexityやCoherenceといった指標を使って、使ってトピック数を設定する方法もあります。以下は、トピック数2~20で、Perplexityを比較しています。Perplexityは小さい程良いので、この結果からは、今回選択したトピック数4が、妥当ある事が言えます。
■python
# Perplexityを使って、トピック数を決定する
n = []
perplexities = []
for i in range(2, 20):
lda = LatentDirichletAllocation(n_components=i, random_state=42)
lda.fit(vec)
n.append(i)
perplexities.append(lda.perplexity(vec))
print(f'num_topics: {i}, perplexity: {lda.perplexity(vec)}')
# 可視化
plt.plot(n, perplexities, marker='o')
plt.xticks(n)
まとめ
潜在的ディリクレ配分法を使って、データセットに含まれるテキストの中身を大枠で分類することができ、理解を深めることができました。感情分析にあたっては、この結果を特徴量として利用したり、トピックごとにさらに深掘りをするといった使い方が考えられます。